トレジャーデータで実践:Basket 分析(応用編2)
本記事は移転しました。新サイトにリダイレクトします。
はじめに
トレジャーデータはクラウドでデータマネージメントサービスを提供しています。
今回はバスケット分析シリーズの第5回(応用編2)となります。
意外性のあるペアの発見
さて,これまで共起度または共起係数の高いアイテムペアを上から見ていきましたが,実はほとんどの共起回数/係数の高いペアは同カテゴリ・同サブカテゴリ内の類似品(または当たり前のペア)であったりします。
カテゴリ同士の共起係数(Cosine Coeff)比較
ここでは Goods Id ではなく2つ上の階層の Category 同士の共起係数を見ていきます。ここからは Cosine 係数を扱っていきます。

Cosine 係数は式:| A ∩ B | / sqrt ( | A | * | B | ) で表される共起係数の一種です。単純な共起回数や癖の強い Simpson 係数とは違って,扱いやすい係数です。(共起係数については実行編をご参照下さい。)

上のテーブルはカテゴリ間の共起係数をヒートマップによって可視化したものです。当然ですが,同カテゴリ内のアイテム同士(対角線上)の共起係数が高いことがわかります。
異なるカテゴリ間の共起係数の高いペア
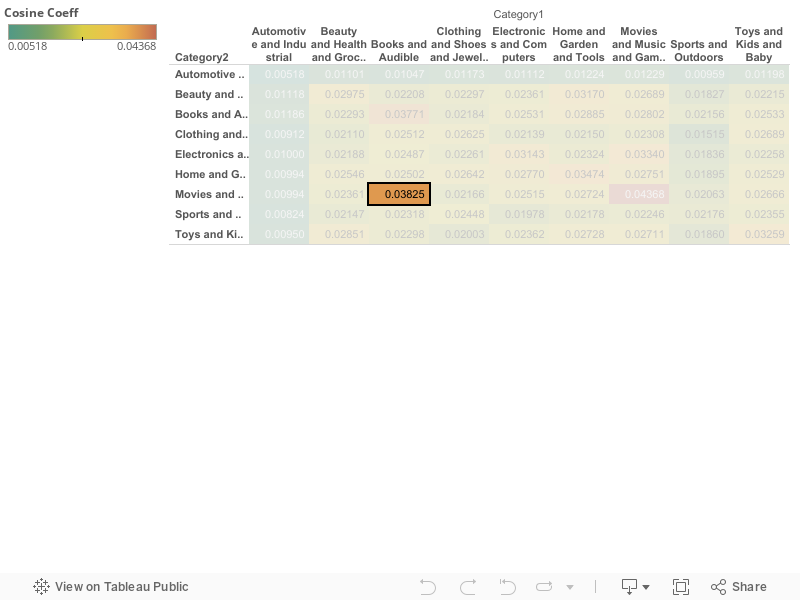
今回は異なるカテゴリで,共起係数が高いペア(意外性を秘めたペア)を発見する手順を見ていきましょう。今回は異なるカテゴリとしては共起係数の高い
「Books and Audible」×「Movies and Music and Games」
のカテゴリの共起係数にフォーカスしていきます。
サブカテゴリ同士の共起係数(Cosine Coeff)比較
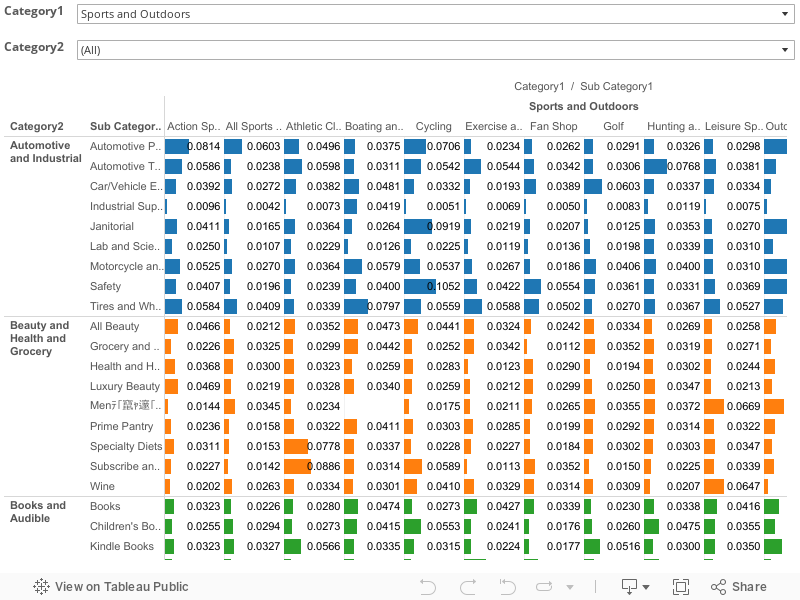
上のバーテーブルはサブカテゴリ:「Sports and Outdoors」に共起する他の全サブカテゴリとの共起係数を表しています。このように縦横に延びる多数の項目を持つ場合,かつセルの値がそれほど差違の無い今回のようなケースでは,ヒートマップ(色による識別)よりバー(バーの長さによる識別)が有効です。
「Books and Audible」×「Movies and Music and Games」

上は再びヒートマップで,共起係数の高かった「Books and Audible」×「Movies and Music and Games」カテゴリ内でのサブカテゴリ同士の共起係数を可視化したものです。
カテゴリと同様に,同サブカテゴリ内(対角線上)の共起係数が高いことがわかります。
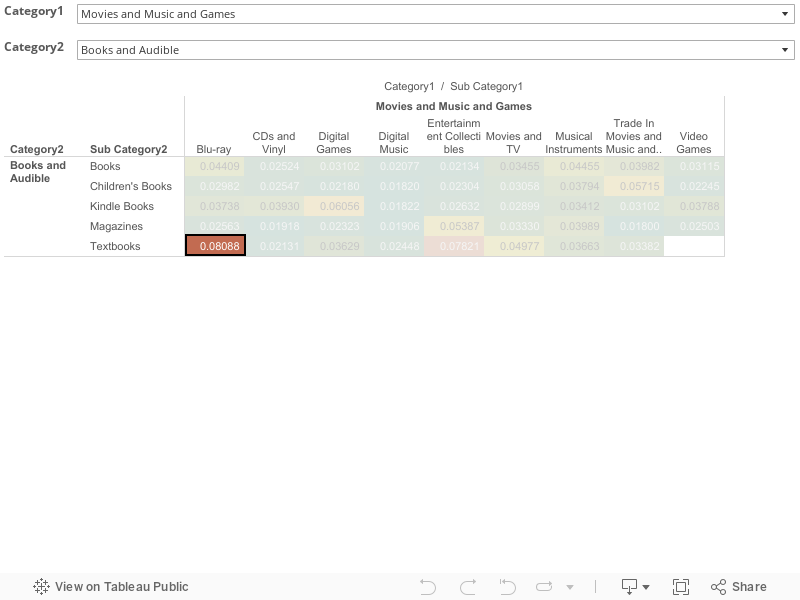
↑ その中で異なるサブカテゴリのペア,「Blu-ray」×「Textooks」に着目してみましょう。
意外性のあるアイテム同士の共起係数
さてここまでで絞れましたら,改めてアイテム同士の共起係数テーブルを見てみます。今回はツリーマップにて,共起係数の高いペアが目立つように工夫しました。
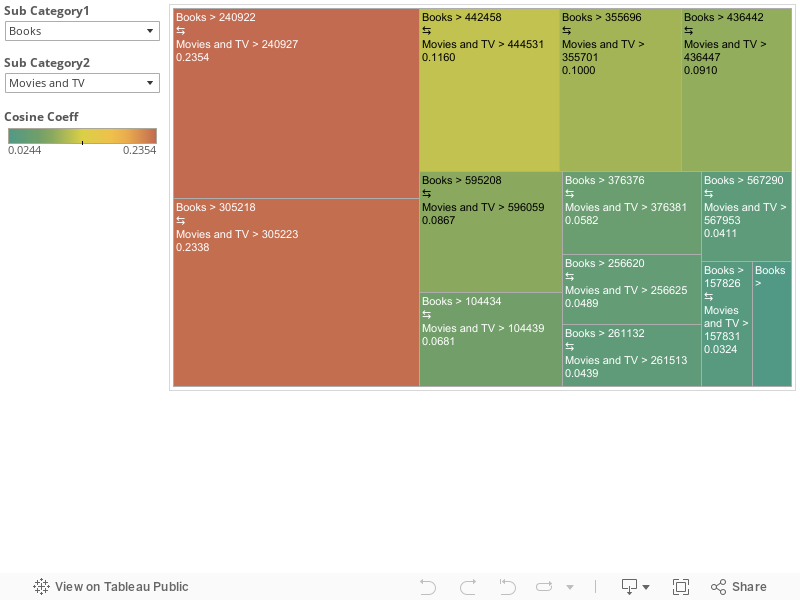
さあ,これで意外性のあるペアを発見できましたね。
- 「Books > 240992」×「Movies and TV > 240927」
- 「Books > 305218」×「Movies and TV > 305223」
です。今回はサンプルデータなので Goods Id の具体的な名称は定義しておりませんが,これがきちんと Goods Name が振られていれば,分析は寄り面白いものになった事は間違い有りません。
皆様のデータでもこのようにして意外性のあるペアを見つけて見て下さい。
次回は,「共起」から「遷移」へ,バスケット分析の概念をリコメンデーションロジックへと拡張していきます。