トレジャーデータで実践:A/B テスト(実践編その2)
本記事は移転しました。新サイトにリダイレクトします。
トレジャーデータはクラウドでデータマネージメントサービスを提供しています。
前回,A/Bの平均値の差違について,サンプル数が多い場合に適用できる「z検定」と喚ばれる最も一般的な手法についてポイントと手順を説明しました。今回は前回の続きで,
Q. あるデパートが特定のカテゴリ商品で「会員なら10%ポイント還元」セールを実施した。このセールに効果があったとすれば,セールを実施したカテゴリで会員(A)/非会員(B)で平均購買単価に違いが見られるはず。
の事例に対して考察を進めて行きます。特に正しくテストできなかったカテゴリについて,それを発見しやすくするための手法および可視化について説明します。
計画的なテストと網羅的な(後付け)テストの区別
まず前回扱った事例について,本記事内で一つ定義をしておきます(本来は前回に記述しておくべきでした,すいません)。
本来のA/Bテストは,サンプルの収集の前に「何について差違を見るのか」(例えばリンクの色や広告の配置の違い)をきちんと立て,他の部分は変わらないように設定することで,A/Bテストは純粋にその「箇所」に差違があったかどうかを判定してくれるものです。ほんの小さな違い故に,心の準備編で述べたように,感覚では難しい差違となって,判断を統的手法に委ねることが必要です。
逆に複数の箇所に違いがあるAとBに対してのテスト結果は「何について」差違があったかが明確では無く,判定自身の有効性についても注意が必要です。
しかしながら実際のシーンでは,データの結果を見て「AとBは変わったのか?」という考察が生まれ,気になる結果を後から網羅的にテストする場合が良くあります。データさえ蓄積していればいつでも実行できるこちらの手法は,人間の意思決定をサポートするものとして非常に有効なものになります。
本記事でとりあげているA/Bテストはこちらの方です。伝統的なA/Bテストを区別するために以下の定義を行います。
計画的なテスト:
テスト実施前に小さな変更箇所を定め,サンプル数と偏りが問題無い理想的な環境で実施した結果に対するテストを「計画的な」テストと呼ぶことにする。
網羅的なテスト:
無計画に取得されたデータに対して,差違があったのかを後から判定したい場合に実施されるテストを「網羅的な(後付け)」テストと呼ぶことにする。
本記事で紹介しているテストは後者の方になります。
A/Bテストを可視化する
AとBの違いは,ヒストグラムとボックスプロットによって可視化することが可能です。特に網羅的なテストでは,この可視化によって
- そもそも比較しなくても明確な差があるもの,
- 分散の偏りがありすぎてテストが機能しないもの
をフィルターすることができます。
ヒストグラム

ヒストグラムは,AとBの分布の形を視覚的に示してくれます。上の例では左の「ラーメン」カテゴリは,上(会員)と下(非会員)の分布の形が似たようなものであることがわかります。一方で右の「乾豆・米類」カテゴリは,分布の形(頂点の位置)に違いがあるように見受けられます。
ボックスプロット
ボックスプロットは,ばらつきのあるデータをわかりやすく表現するための統計学的グラフです。データが集中している箇所を箱として表示し,中心から上下に外れた箇所は線(ひげ)とプロットで表現しています。

AとBについての差違を箱のずれ具合で比較するのはとても有効な方法です。そもそも箱の部分が交わっていないカテゴリ(上の例では「催事1」「昆布」)は差違が明らかでテストのフォーカスから外れることを教えてくれています。
一方「催事3」や「牛乳」カテゴリでは,重なる部分の多い箱を持ち合わせており,差違があるかをテストする価値のあることを教えてくれています。
P値とその可視化
前回のA/Bテストでは,有意水準5%,10%で Reject (棄却:有意な差がある)するか Accept(有意な差が認められない)という判定のみを行いましたが,こちらもP値を求めるによって可視化することができます。

P値とは,帰無仮説H0: μA=μB の元で求められたz分布に従うはずの統計量Tが,どれくらいの確率で現れたものかを教えてくれます。
有意水準5%の元での両側テストでは,「Tが2.5%(両側足して5%)よりも低い確率で現れたものであれば,前提としたz分布に従うという仮説を否定する」ことで有意な差を認めます。
よってこのP値が有意水準より小さいものであればあるほど「有意な差がある」と確信を持つことができますので,この数値は Reject/Accept の2値判定の代わりに使うことができます。
トレジャーデータでは z分布テーブル をインポートすることで,以下のテンプレートクエリでレポートを作成する事が可能になります。
さらに前回の後ろで考察した「片方の分散が大きすぎてテストが機能しない」点も,分散比をプロットの大きさとしたP値プロットで発見することが可能になります。
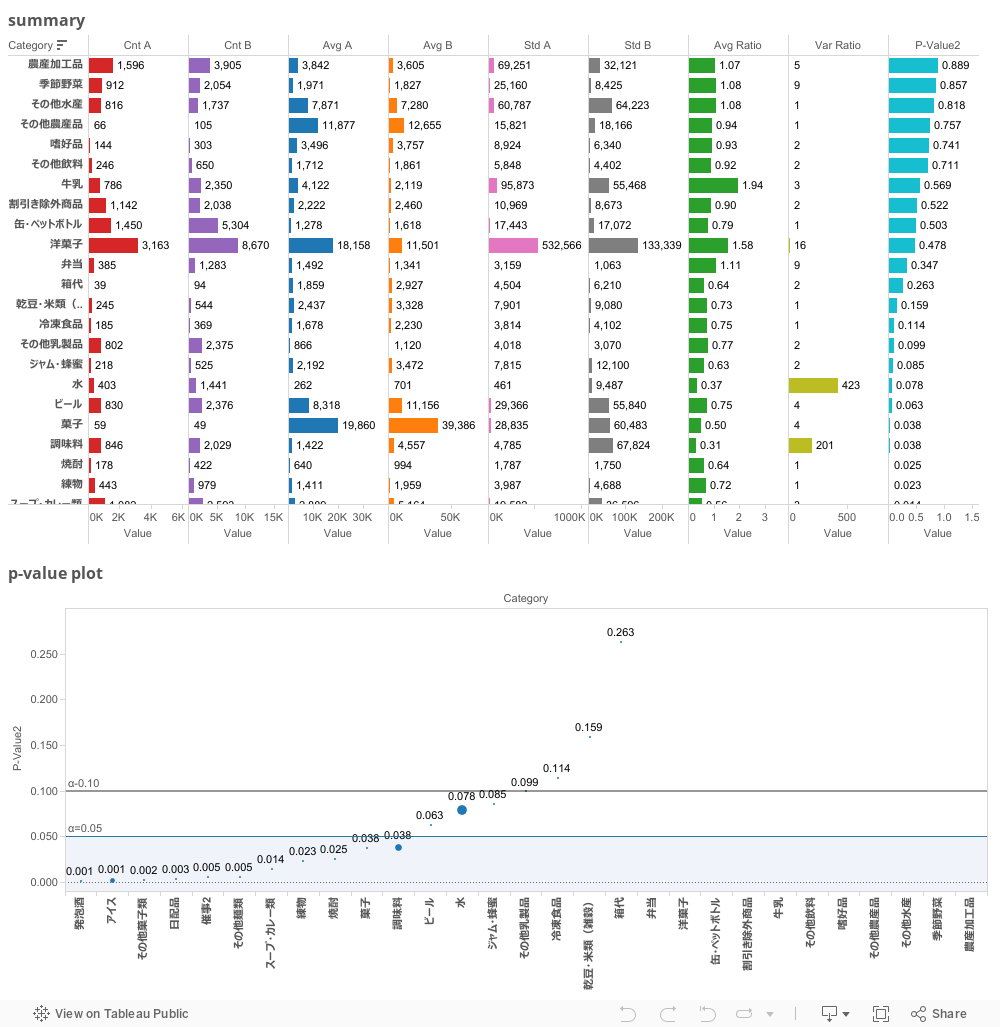
上のA/Bテスト結果レポートでは,それぞれのカテゴリでの会員(A)/非会員(B)の有意な差をP値でソートしたテーブルと,P値を分散をバブルの大きさにしたプロットを表現しています。前回問題視した「水」カテゴリは,特異な点として目立つようになっていますね。